
Mamba 模型在视觉上的开发
Mamba 模型在视觉上的开发
状态空间模型(State Space Models)
用于预测连续序列在给定输入下的下一状态。
固定动态特性
Mamba
Mamba 是一种基于 选择性状态空间模型(Selective SSM) 的序列建模架构,它最大的特点是:
- 时间复杂度和显存复杂度都是 线性 O(L)
- 非常擅长 长序列建模
- 可以作为 Transformer Block 的高效替代
目前已经在 NLP、Vision 以及多模态领域 都有广泛应用。
从本质上看,Mamba 用 SSM 来建模序列依赖,避免了自注意力的二次复杂度瓶颈。
MambaVision: A Hybrid Mamba-Transformer Vision Backbone
这篇文章是英伟达更改Mamba结构然后在视觉任务上的一次尝试。
核心问题
- transformer 计算瓶颈(n2)
- 原生Mamba在视觉任务上局限性
创新点
- 专为视觉设计的Mamba模块:MambaVision Mixer
- Mamba与Transformer混合新架构
- 分层设计
架构设计
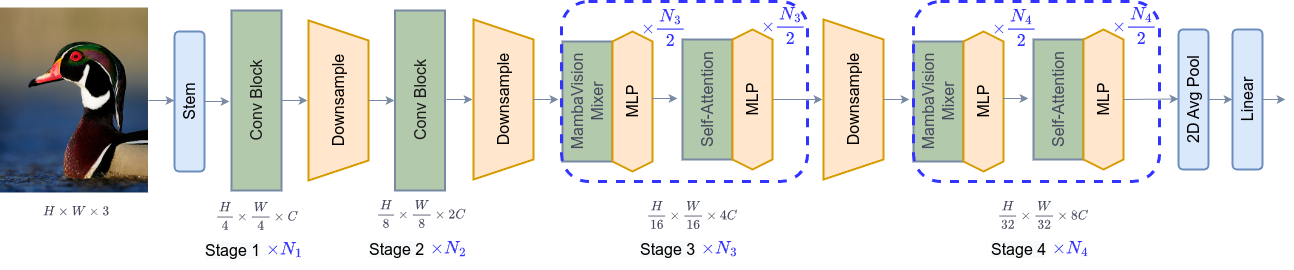
- 在高分辨率图像输入后先用卷积层进行下采样(前两个阶段)
- MambaVision blocks 进行深度特征的序列建模,Transformer blocks 恢复丢失的全局上下文并捕获长程空间依赖性。
先用 MambaVision Mixer 提升 token 的全局语义一致性
再用 Transformer 精修空间关系
RoMA: Scaling up Mamba-based Foundation Models for Remote Sensing
这篇论文是讲Mamba模型应用到遥感图像领域,专注于高分辨率遥感图像中的多尺度视觉任务。
RoMA 主要有三点贡献:
- 它是首个面向遥感的 Mamba 自监督自回归预训练框架。
- 提出了 动态旋转感知机制,应对目标方向任意的问题。
- 设计了 多尺度预测目标,解决遥感中目标尺度变化极大的问题。
自回归预训练策略
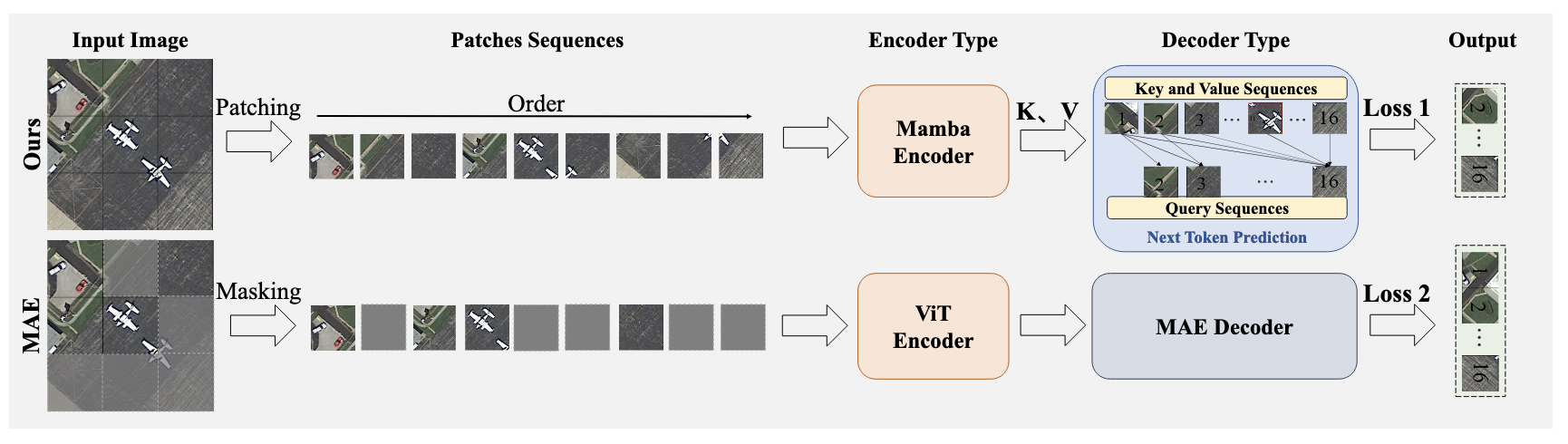
在预训练策略上,RoMA 和 MAE 有本质区别。
- MAE 只编码部分可见 patch
- RoMA 用 Mamba 编码 所有 patch
同时: - MAE 是重建被 mask 的区域
- RoMA 是预测 下一个 token
这种自回归方式与 Mamba 的顺序建模特性是天然契合的。
自适应旋转编码
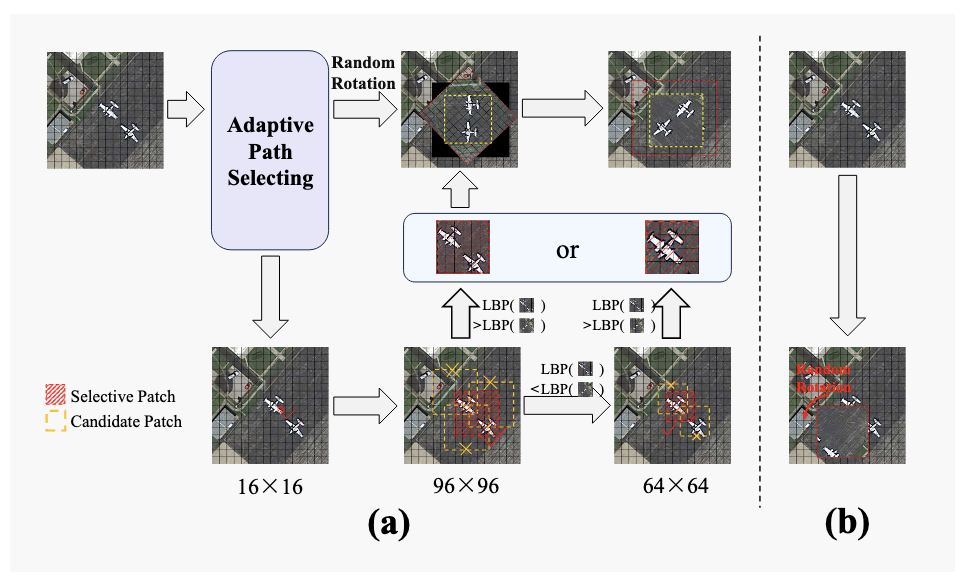
针对遥感目标 方向任意、分布稀疏 的问题,RoMA 提出了自适应旋转编码策略。
核心包括两点:
- 使用 LBP 算法筛选高价值区域进行旋转增强
- 显式引入角度嵌入,提供方向先验
这显著提升了模型对旋转不变性的感知能力。
多尺度预测 & 可扩展性
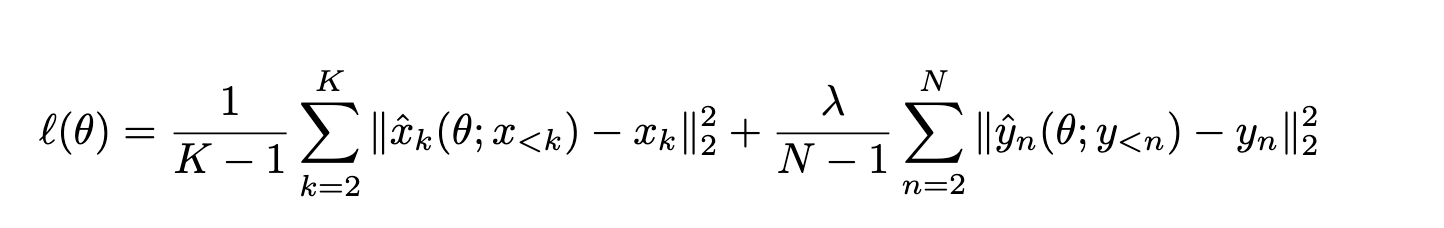
在多尺度方面,RoMA 不仅计算每个 patch 的 loss,还计算 patch 组合形成的 簇级别 loss。
这让模型同时关注:
- 小目标
- 大结构
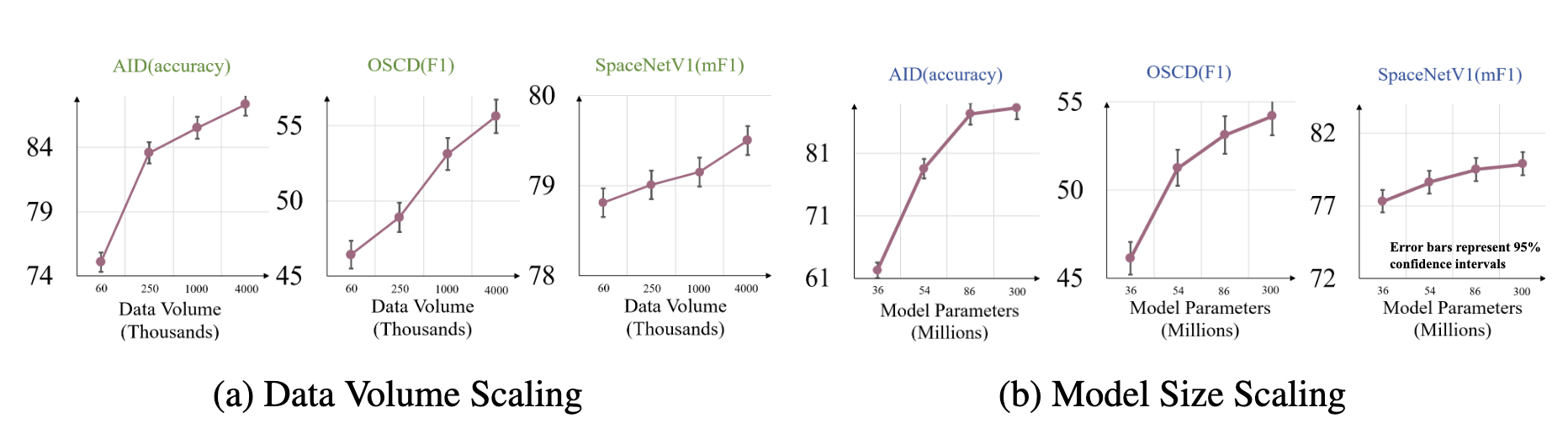
同时实验表明:
- 数据越多,效果越好
- 模型越大,效果越好
具备良好的基础模型扩展性。
下游任务 & 总结
在下游任务上,RoMA 在场景分类、变化检测和语义分割中都取得了优异表现。
特别是在线性探测设置下,小目标效果依然很好,说明预训练特征质量很高。

在 1248×1248 分辨率下,相对于ViT模型,
- 显存降低近 79%
- 推理速度提升 1.56 倍
引用
PS: 封面来自这里
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Comments




